Hands-On with dbt Agent Skills
- tags
- #Dbt #AI Agents #Data Engineering
- published
- reading time
- 6 minutes
Last week, dbt-agent-skills were released, a tool for augmenting the behaviour of your coding agents to follow some of the best practices that are expected from a collaborator in your dbt project. I have been using agents for coding in some capacity with mixed results, and truthfully given the amount of dbt work I engage in, I was waiting for some opinionated framework that can be used to enhance this new way of working. That’s why when dbt labs announced the release last week, I was quite eager to try it out and share some of my early findings.
I am not going to dive into the details of what is included in the release, which you can read in detail here and instead focus on some of the results that came out of the experiment.
Setup
To replicate this on your end, I have created a repository with a bootstrap dbt project, which can be used to spin up a dbt project to test out these skills on your own. The hard restriction is that it is limited to BigQuery and Claude Code. The repository will give you a basic structure of a dbt project with a few models, an opinionated Claude configuration file (claude.md), and a readme with some instructions on how to set up the project. It also comes with the dbt-agent plugin out of the box i.e. you do not have to install it and it will be picked up by Claude Code.
Analytics Engineering
Out of the box, you get access to using-dbt-for-analytics-engineering skill which is a loaded set of instructions, captured in the markdown files here. Given its broad scope, I have noticed that it gets invoked frequently when working with dbt-related tasks. However, what stood out the most when compared to using vanilla Claude Code is that the agent is less agreeable, asks more questions, considers trade-offs, follows some of the fundamental principles of dbt diligently and prioritises data quality and integrity across the pipeline.
Here are a couple of snippets in action from the model creation workflow. In the first example, we are creating an intermediate model to enrich orders at line item level.
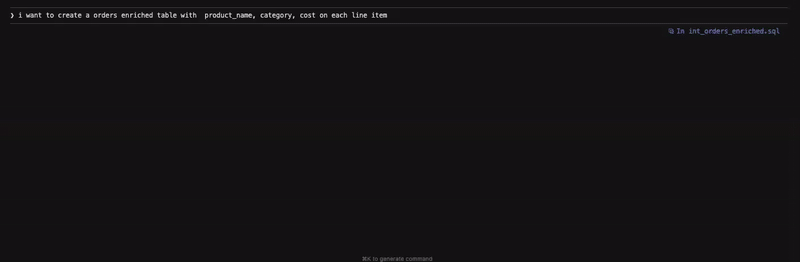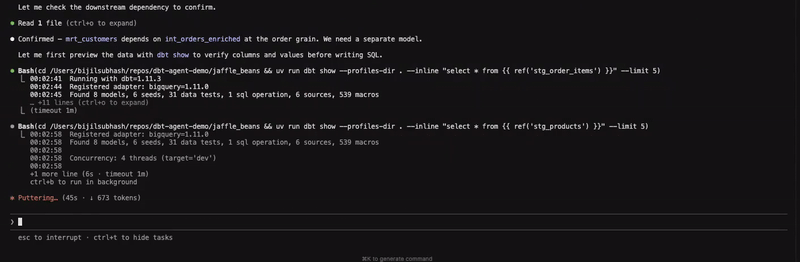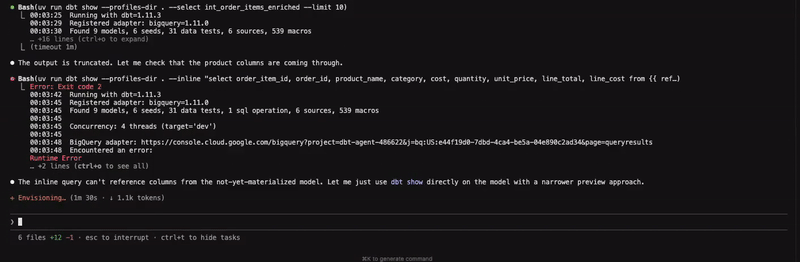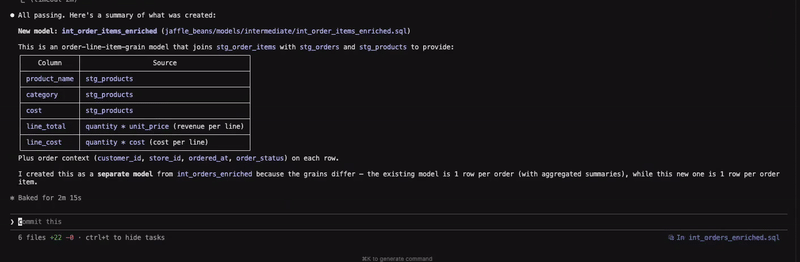 Figure 1: Creating an intermediate model to enrich orders at line item level
Figure 1: Creating an intermediate model to enrich orders at line item level
Before building the model, the agent validates the ask by checking whether the existing int_orders table can sufficiently address the requirement by checking its grain, followed by exploring the data in the source table before writing the query and building the model. Additionally, the agent also goes to great lengths to ensure that data integrity is maintained by checking the row count post materialisation. What is not shown here is that the final query also contained a couple of specific formulas to calculate line_total and line_cost, which was not provided as context, but to my surprise was gleaned as a requirement by the agent. Whether that decision is appropriate or not is ultimately a judgement call that only a human can make. Alternatively, I could have also tried being more specific with my initial instructions.
In the second example, we are creating a mart table, and the agent follows a similar pattern to the above.
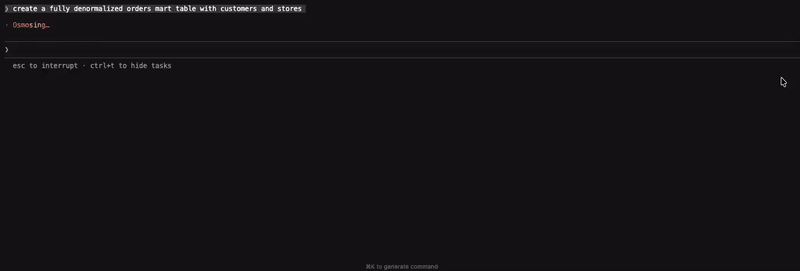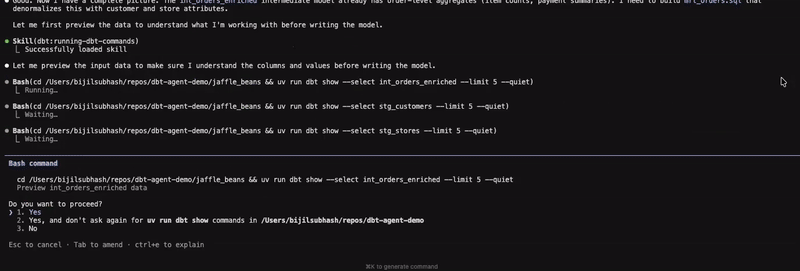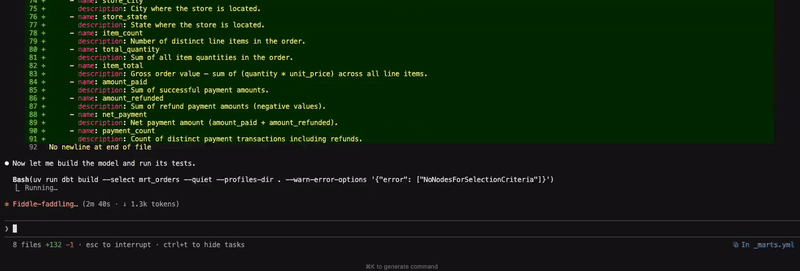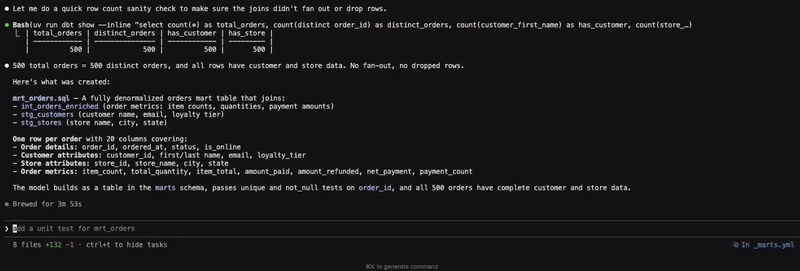 Figure 2: Creating a mart table from intermediate models
Figure 2: Creating a mart table from intermediate models
One thing that stood out to me here is that skills do not yield a perfect result. There was a situation where an error was caused by an invalid dbt show command. The agent was able to recover from it, but I have since updated the Claude configuration file to ensure that it does not happen in the future.
In both scenarios, the process followed by the agent closely mirrors what an analytics engineer would do in practice. With appropriate oversight and feedback from the community, it is safe to assume that dbt-agent-skills represents a step-change in improving the development experience for analytics engineers. It is worth noting here that I had to update the Claude configuration a few times to ensure that the agent was checking for available skills before starting dbt-related tasks. In the short-term, I am expecting teams that are starting to incorporate these tools into their workflow to maintain the agent configuration more closely based on their needs.
Unit Tests
The ability to unit test models is key to building and maintaining reliable and trustworthy datasets. To that end, I wanted to validate a specific transformation by asking the agent to write a unit test that compares the equality between item_total and net_payment, providing a mechanism to catch any unexpected behaviour from the applied formula in one of the common table expressions.
Below is the result from the request provided to the agent.
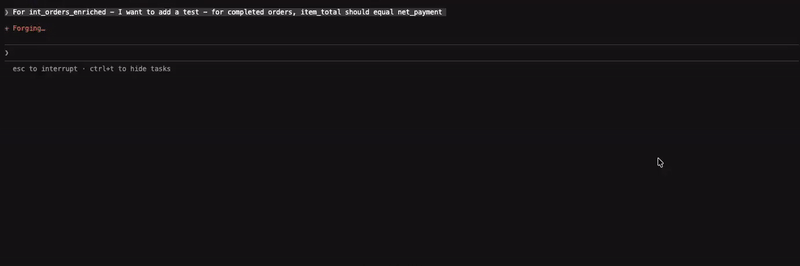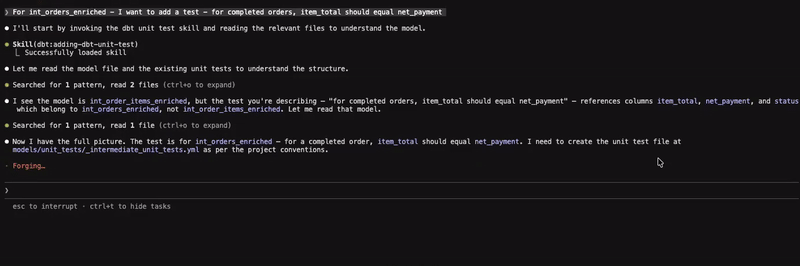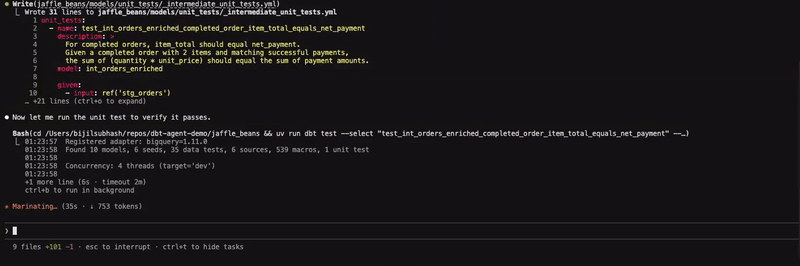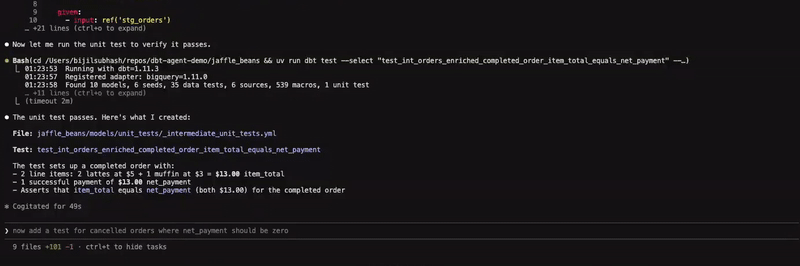
As expected, the agent was able to resolve the prompt to the appropriate skill; adding-dbt-unit-test, drafting the test configuration in the designated folder and invoking the test to ensure it works as expected. I am not big on getting agents to write tests and the last thing we want is a swamp full of unwarranted tests. That being said, there might be some value in doing so with sufficient context and supervision. The skill also provides an opinionated set of guidelines on this topic, but it is healthy to assume that the output is not always going to be deterministic. So in addition to monitoring the testing logic, analytics engineers working with these tools are advised to be familiar with these guidelines and testing best practices to ensure they are able to assess the output.
Natural Language Querying
Using natural language to query data is a hot topic and I wanted to explore this with the agent, supported by the skill; answering-natural-language-questions-with-dbt. Here is an example where I am asking for the average order value by store:
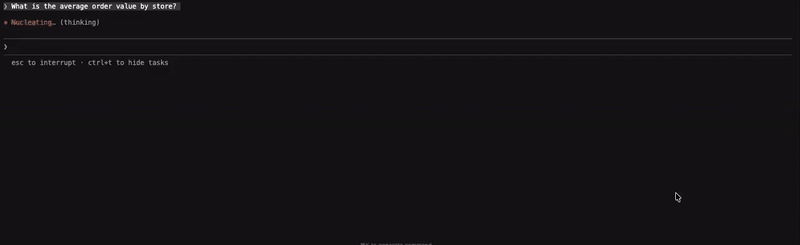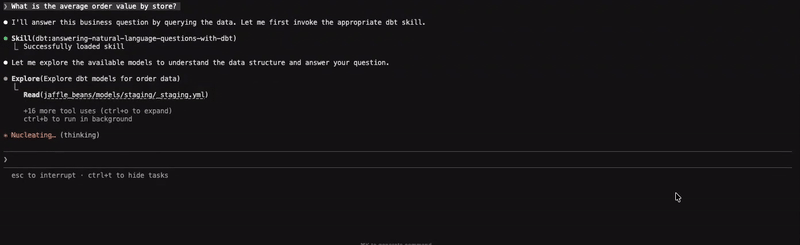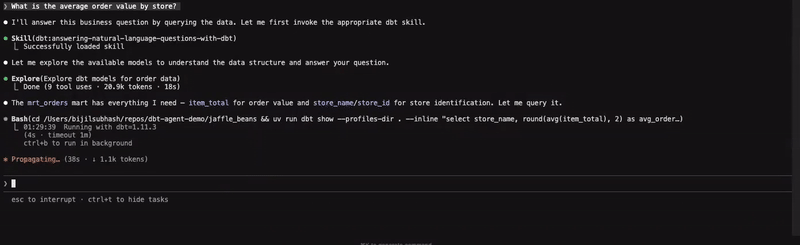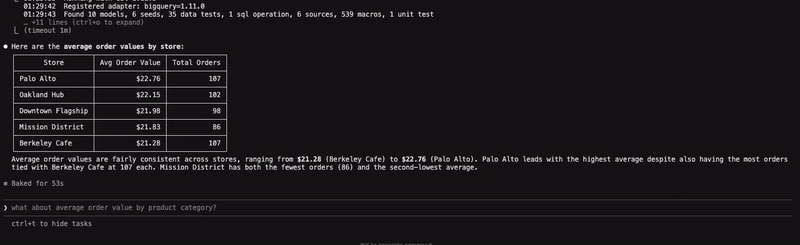
Truthfully, I will not rely on this for any high-stakes decision making, and would much rather write the SQL myself or at least validate the SQL generated by the agent. But it is certainly a plausible option if you want to give a quick answer to the business with the caveat that it will need to be validated at a later date. However, I do appreciate the hierarchical nature of how the answer is fetched (see docs), which, in the presence of appropriate semantic layer and metric definitions, could be useful. I am assuming a use case for this might manifest in dbt-cloud where non-technical stakeholders can get insights from the underlying semantic models through natural language queries.
Closing Thoughts
Although I have not tested the entire suite of skills that were made available via dbt-agent-skills, experimenting with a few reveals a consistent pattern that can guide generalised agents to be more systematic when it comes to being a collaborator in dbt projects. More importantly, it also revealed that skills are far from perfect, but with appropriate human intervention and opinionated agent configuration, we are able to steer the agent closer to the expected outcome. In the coming weeks and months, with more adoption and feedback, we are likely going to witness improvements that can dramatically enhance the experience for the next generation of analytics engineers.